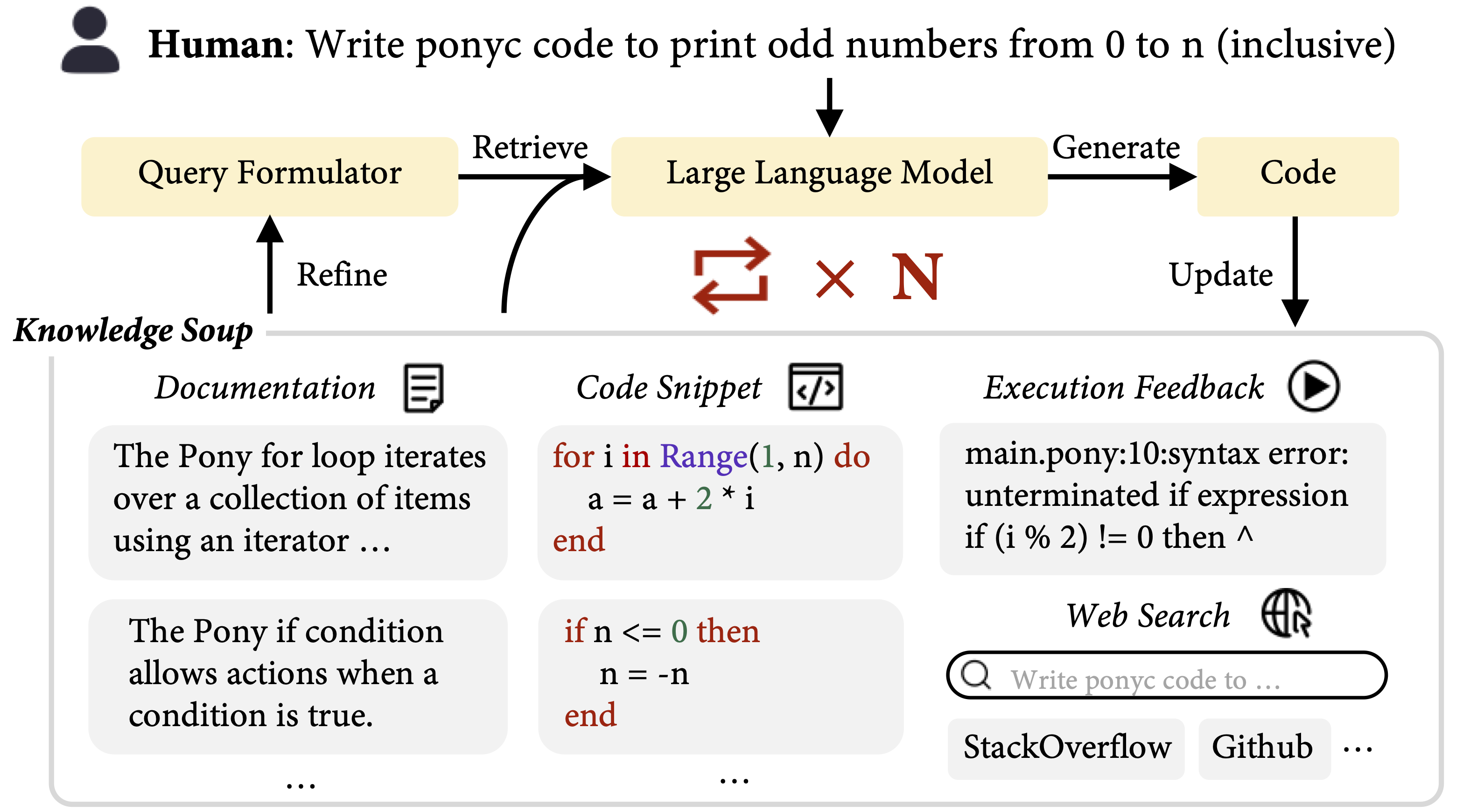
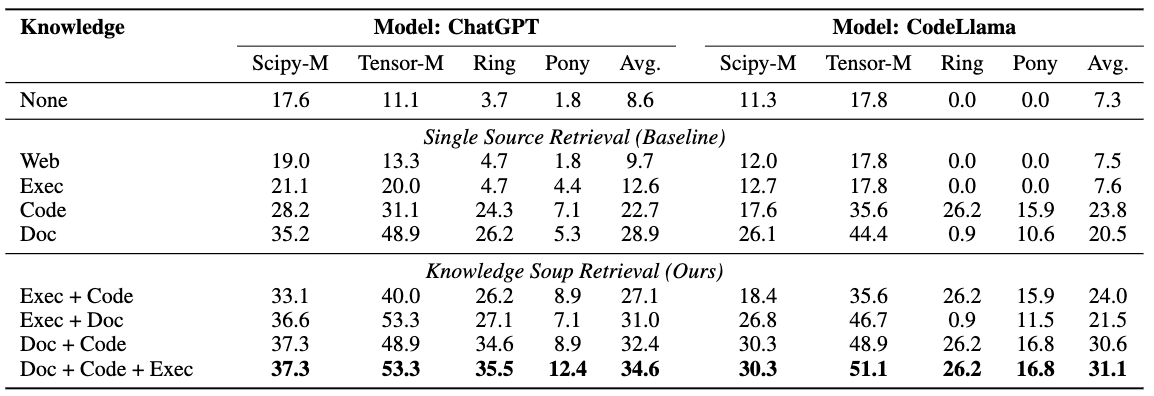
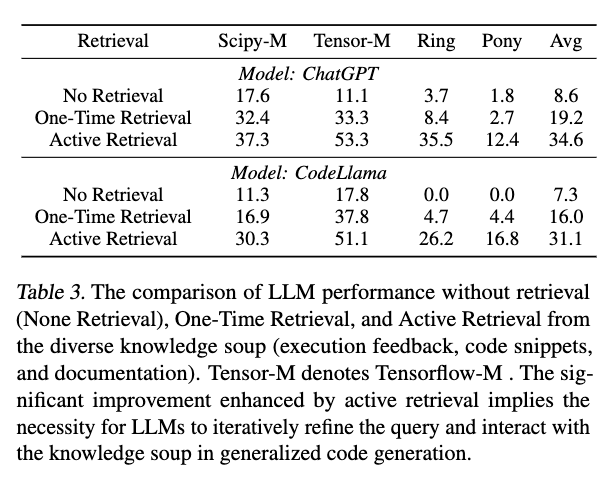
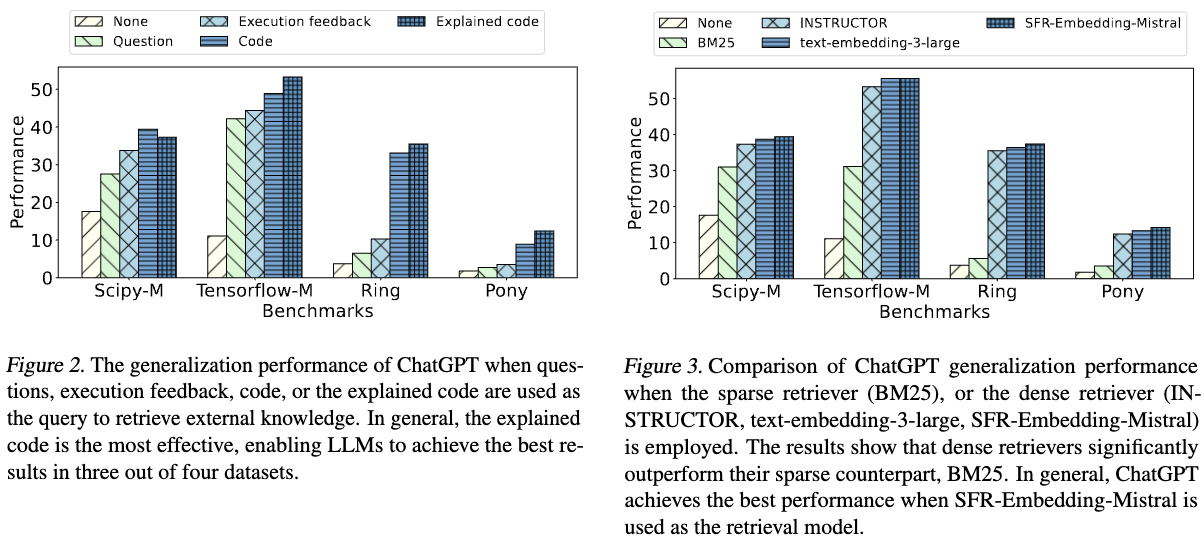
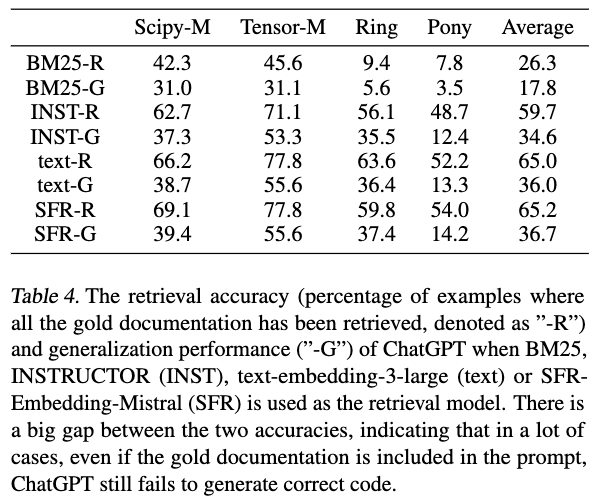
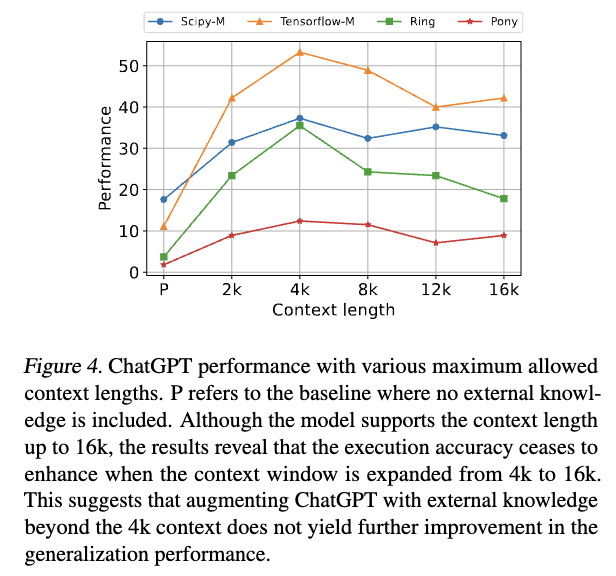
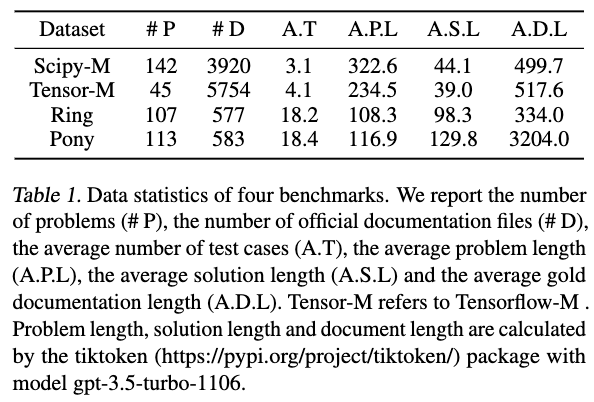
We introduce EVOR, a general pipeline for retrieval-augmented code generation (RACG). We construct a knowledge soup integrating web search, documentation, execution feedback, and evolved code snippets. Through active retrieval in knowledge soup, we demonstrate significant increase in benchmarks about updated libraries and long-tail programming languages (8.6% to 34.6% in ChatGPT)